Inside Git: How It Works and the Role of the .git Folder
Inside Git: How It Works and the Role of the .git Folder
A quiet folder most people ignore
When you run git init, Git creates a folder named .git.
Most beginners never open it.
Some are even told, “Don’t touch it.”
But here’s the truth:
Everything Git knows about your project lives inside
.git.
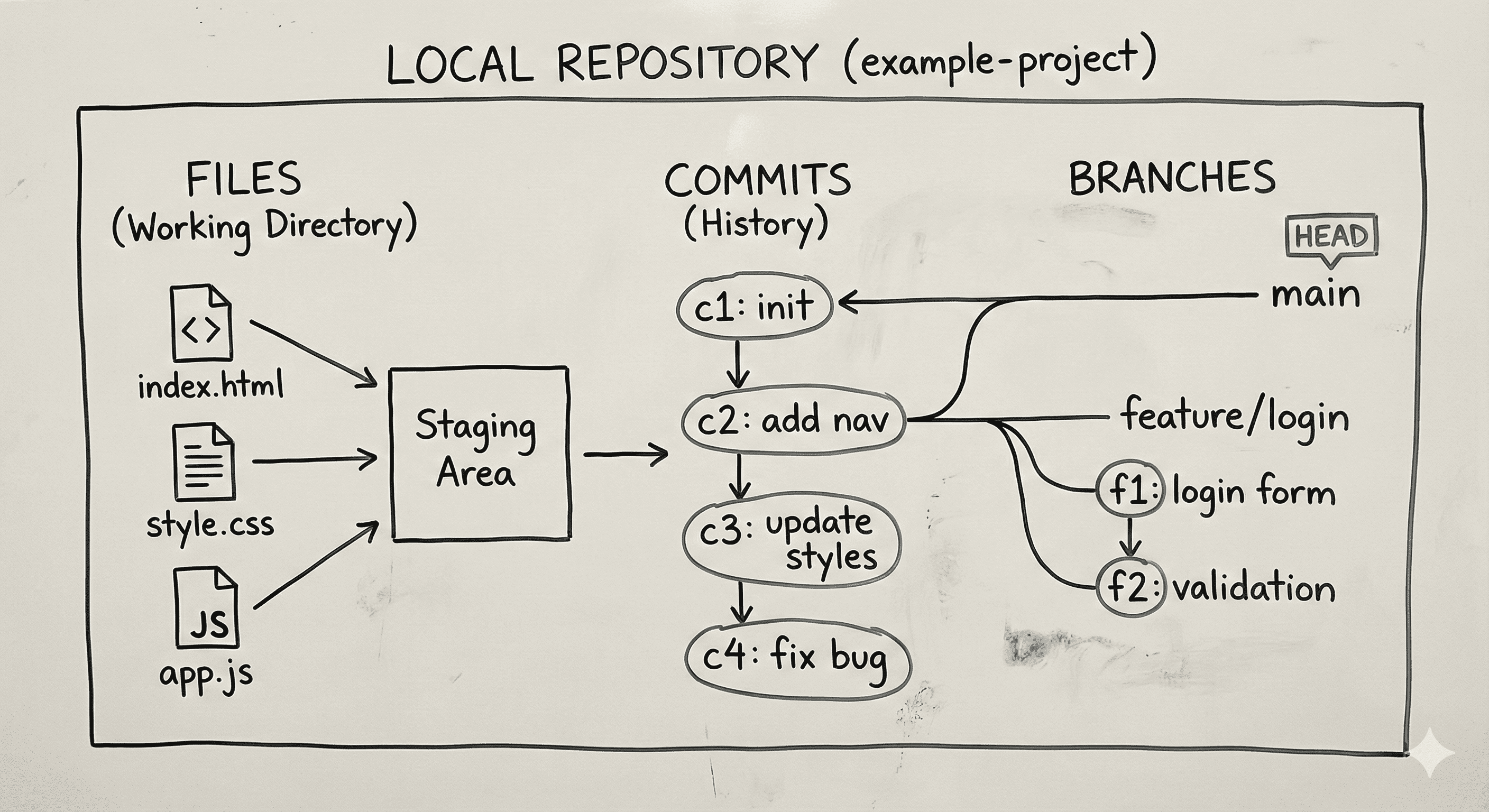
Your files are just files.
The memory, history, and intelligence of Git live elsewhere.
Understanding this folder builds a mental model of Git—so you stop memorizing commands and start understanding behavior.

What the .git folder really is
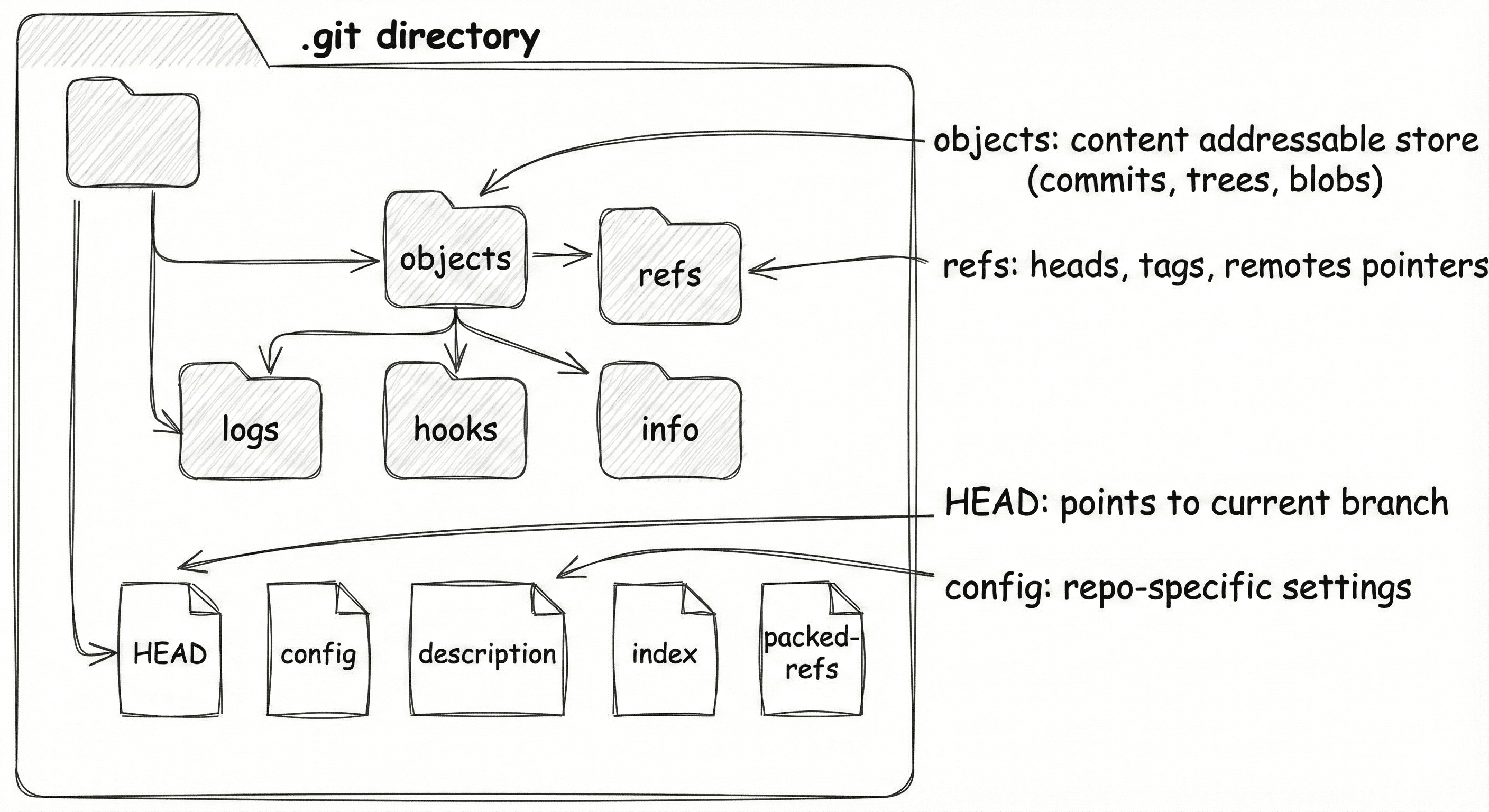
The .git folder is Git’s internal database.
It stores:
Every version of every file
Every commit
Every branch
All relationships between changes
If you delete .git, your files remain—but Git forgets everything.
A good analogy:
Your project folder = the notebook you write in
.gitfolder = the brain that remembers every edit you’ve ever made
Why Git needs its own internal system
Git does not track files the way cloud storage does.
It does not say:
“Here is version 1, here is version 2.”
Instead, Git says:
“Here is a snapshot of the entire project at this moment.”
To do this efficiently and safely, Git breaks your project into objects.
Git objects (the building blocks)
Internally, Git stores only three core object types:
Blob
Tree
Commit
Everything else is built on top of these.

Blob (file content)
A blob represents the content of a file.
Important detail:
Blob does not store file names
Blob stores only the data
If two files have the same content, Git stores one blob, not two.
Think of a blob as:
“The text inside the file, nothing else.”
Tree (folder structure)
A tree represents a directory.
It stores:
File names
Folder names
References to blobs or other trees
Trees connect structure to content.
Think of a tree as:
“This folder contains these files and subfolders.”

Commit (a snapshot + metadata)
A commit ties everything together.
A commit contains:
A reference to a tree (project structure)
A reference to the parent commit
Author and timestamp
Commit message
A commit does not store files directly.
It points to a tree, which points to blobs.
This design is why Git is fast and reliable.
How Git tracks changes (not line by line)
Git does not track edits like “add this line, remove that line.”
Instead, Git:
Takes a snapshot of file contents
Stores only what changed
Reuses unchanged blobs automatically
This is why commits are cheap and branching is fast.
What really happens during git add
When you run:
git add file.js
Internally, Git does this:
Reads the file content
Creates a blob object
Stores it inside
.git/objectsUpdates the staging area to point to that blob
Nothing is committed yet.
Git is just preparing data.
The staging area is a draft table, not history.
What really happens during git commit
When you run:
git commit -m "Add validation"
Git performs these steps:
Takes everything from the staging area
Creates tree objects for folders
Creates a commit object
Links the commit to its parent
Moves
HEADto this new commit
Now the snapshot is permanent.
This is why Git forces you to add before committing—it separates selection from recording.
How Git uses hashes (this is critical)
Every Git object is identified by a hash (SHA-1 or SHA-256).
That hash is generated from:
The object’s content
The object’s type
This means:
If content changes → hash changes
If even one character changes → hash changes completely
Why this matters:
Data integrity is guaranteed
History cannot be silently altered
Git instantly detects corruption
Git doesn’t trust filenames.
It trusts math.
Why this design is powerful
Because of this internal structure:
Git can verify history
Git can share data efficiently
Git can branch without copying files
Git can detect tampering
This is why Git scales from student projects to massive codebases.
The mental model to remember
Don’t think of Git as commands.
Think of Git as:
A content-addressed database
That stores snapshots
Built from small, reusable objects
Verified by cryptographic hashes
Once you understand this, Git stops feeling mysterious.
You’re no longer using Git blindly.
You’re working with its design.